LegalNeer
KI-gestützte juristische Analyseplattform als SaaS mit Echtzeit-Streaming, Dokumenten-Wissensdatenbanken und verbrauchsbasierter Abrechnung.
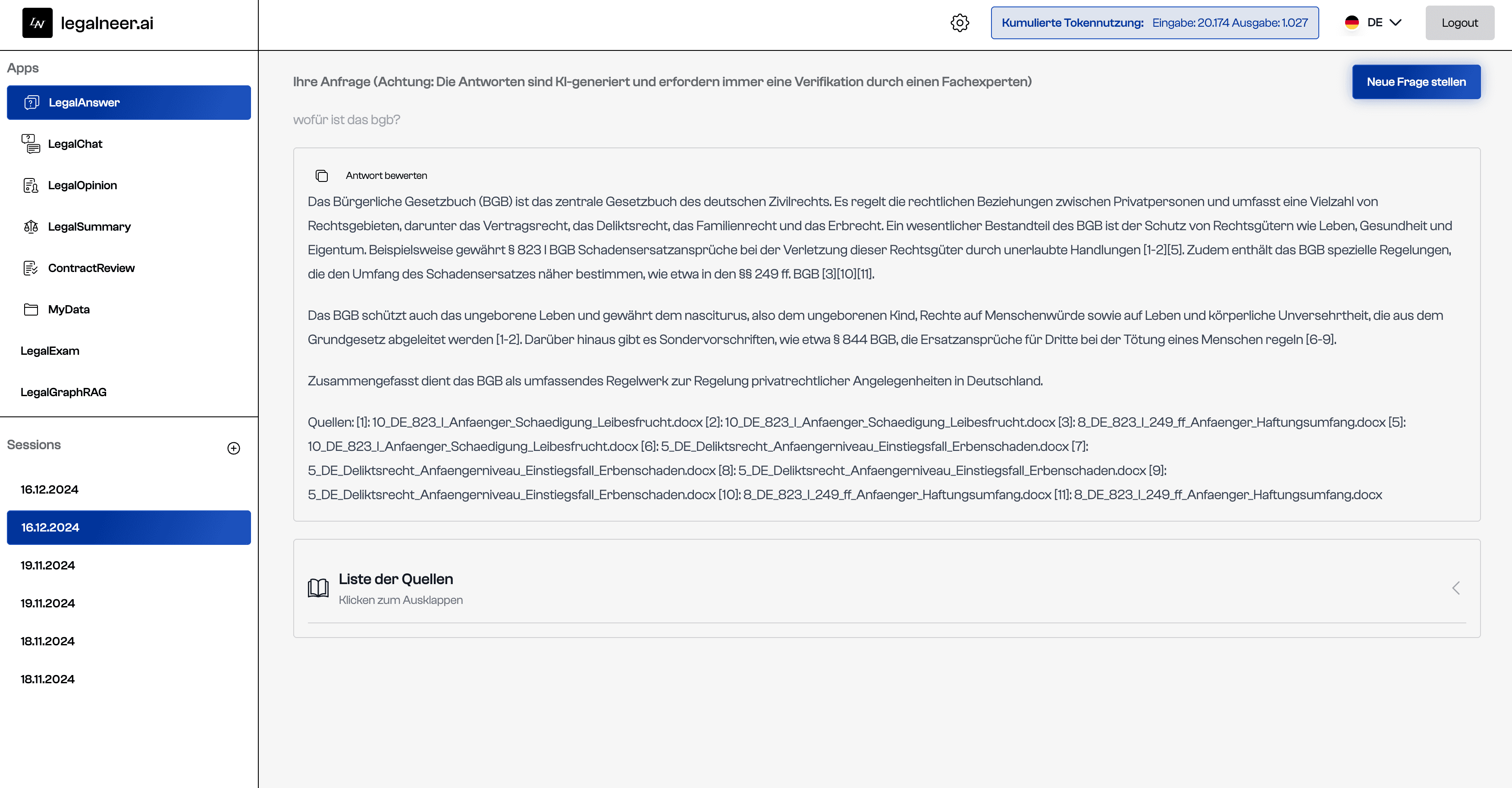
Die Herausforderung
Juristen verbringen erhebliche Zeit mit dem Prüfen, Zusammenfassen und Analysieren von Dokumenten — Verträge, Gutachten, Akten. Bestehende Tools bieten generische KI-Chat-Oberflächen ohne domänenspezifischen Kontext und strukturierte juristische Workflows. Ziel war es, eine Plattform zu entwickeln, die mehrere spezialisierte KI-Anwendungen bereitstellt (Zusammenfassung, Q&A, Chat, Gutachtenerstellung, Vertragsprüfung) — jeweils mit Zugriff auf die eigene Dokumenten-Wissensdatenbank, Echtzeit-gestreamter Ausgabe und granularer Nutzungsverfolgung für die Abrechnung.
Der Ansatz
Die Architektur trennt Verantwortlichkeiten über drei Services: ein Next.js-14-Frontend für die Benutzeroberfläche, ein Django-Backend für Benutzerverwaltung, Dateispeicherung, Authentifizierung und Abrechnung sowie ein FastAPI-Backend zur Orchestrierung LangChain-basierter KI-Chains.
Die Kommunikation zwischen Frontend und FastAPI nutzt eine eigens entwickelte Server-Sent-Events-Streaming-Pipeline — gebaut mit eventsource-parser auf der Client-Seite und sse_starlette auf der Server-Seite — für die Token-für-Token-Ausgabe. Die Authentifizierung basiert auf RSA256-signierten JWTs, die von Django ausgestellt und von FastAPI unabhängig verifiziert werden. Alle Services sind mit Docker-Multi-Stage-Builds containerisiert und über Docker Compose orchestriert.
Implementierung
KI-Chain-Architektur
Fünf eigenständige KI-Anwendungen sind als LangChain Runnables implementiert: Legal Summary, Legal Q&A, Legal Chat, Legal Opinion und Contract Review. Jede Chain kombiniert Prompt-Templates (gespeichert in einer zentralen config.yml), Dokumenten-Retrieval über Pinecone-Vektorsuche (mit konfigurierbaren Similarity-/MMR-Strategien und Cohere-Reranking) sowie OpenAI-Modellausführung. Contract Review nutzt dynamisches Routing — ein Klassifikationsschritt bestimmt den Vertragstyp (z. B. NDA, Dienstleistungsvertrag) und leitet an eine typspezifische Prüf-Chain weiter. Legal Opinion enthält Chain-of-Thought-Reasoning mit strukturierter Ausgabeformatierung.
Streaming-Pipeline
Die Frontend-Route /api/llm/[path]/route.ts fungiert als Streaming-Proxy. Sie instanziiert einen RemoteRunnable von LangChain, streamt Chunks von FastAPI und leitet sie über einen TransformStream an den Browser weiter. Jeder Chunk wird als SSE-data:-Event JSON-kodiert übertragen. Der use-chat-Hook verwaltet Message-State, Abort-Controller und progressives Rendering auf Client-Seite.
Wissensdatenbank-System
Nutzer organisieren Dokumente in hierarchischen Verzeichnissen (umgesetzt mit Django MPTT). Dateien werden in S3-kompatiblen Speicher (Exoscale) hochgeladen, in 2000-Token-Segmente mit 200-Token-Overlap aufgeteilt und mit Metadaten (Dokumenttyp, Rechtsgebiet, Zeitraum) in Pinecone indiziert. Ein FileKnowledgebaseState-Modell verfolgt nutzerspezifische Einschluss-Flags, und eine globale Wissensdatenbank stellt gemeinsames juristisches Referenzmaterial bereit.
Abrechnung & Token-Tracking
Ein eigener TokenUsageCallbackHandler (LangChain-Callback) erfasst Input-/Output-Token-Counts während der Chain-Ausführung und sendet diese per POST an Django. Django protokolliert die Nutzung pro Sitzung und löst Stripe-Meter-Events für verbrauchsbasierte Abrechnung aus. Abo-Stufen (Free, Basic, Pro) steuern den Zugang zu bestimmten KI-Anwendungen über eine PermissionChecker-Dependency in FastAPI.
Auth & Mehrsprachigkeit
JWT-Tokens nutzen RSA256 mit einem Private Key in Django und base64-verteilten Public Keys in FastAPI und Next.js. Social Login (Google, LinkedIn) wird über django-allauth unterstützt. Das Frontend nutzt next-intl für vollständige Deutsch/Englisch-Internationalisierung mit Locale-basiertem Routing.
Ergebnisse
Die Plattform liefert fünf produktionsreife juristische KI-Tools, jeweils mit Echtzeit-Streaming, dokumentenbasiertem Retrieval und Sitzungspersistenz. Die Drei-Service-Architektur trennt UI, Geschäftslogik und KI-Orchestrierung sauber voneinander und ermöglicht unabhängiges Skalieren und Deployment. Die eigens entwickelte Streaming-Pipeline liefert Sub-Sekunden-First-Token-Latenz im Browser. Token-Level-Nutzungsverfolgung ermöglicht präzise verbrauchsbasierte Preisgestaltung. Die Codebasis unterstützt mehrere LLM-Modelle (GPT-4o, GPT-4.1, GPT-4-turbo) mit konfigurationsgesteuertem Wechsel.
Highlights
- Eigene SSE-Streaming-Pipeline für LLM-Ausgabe
- LangChain-basierte Multi-Chain-KI-Architektur
- Hierarchisches Dokumenten-Wissensdatenbank-System
- Verbrauchsbasierte Abrechnung über Stripe
- JWT RSA256-Auth über drei Services
- Internationalisierte Oberfläche (DE & EN)